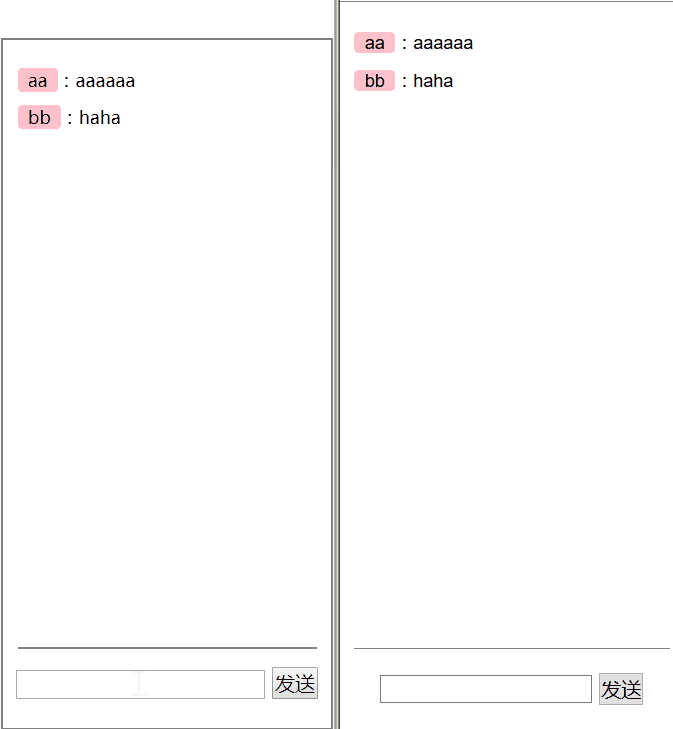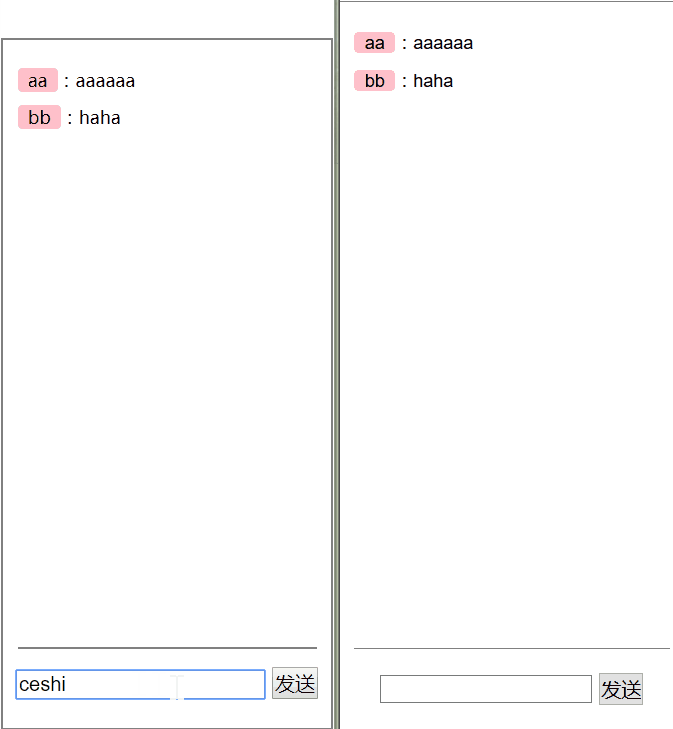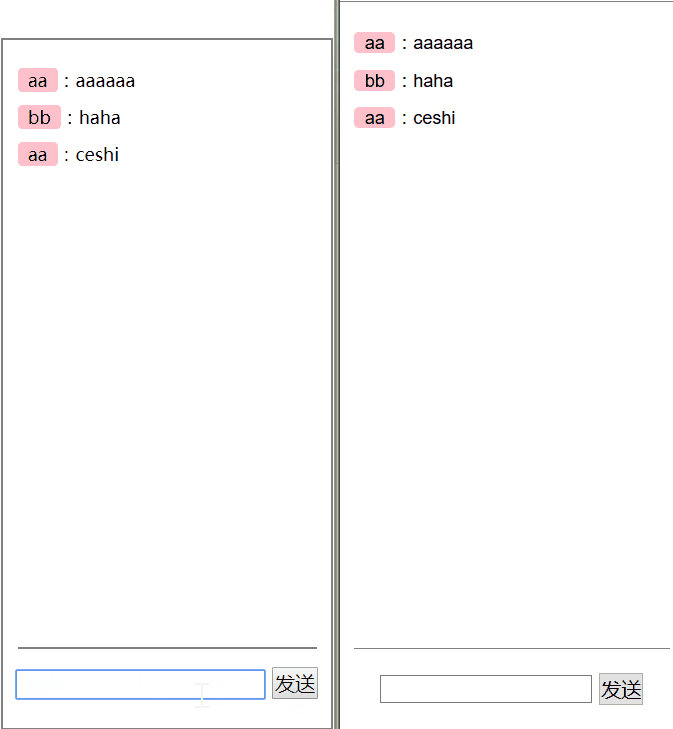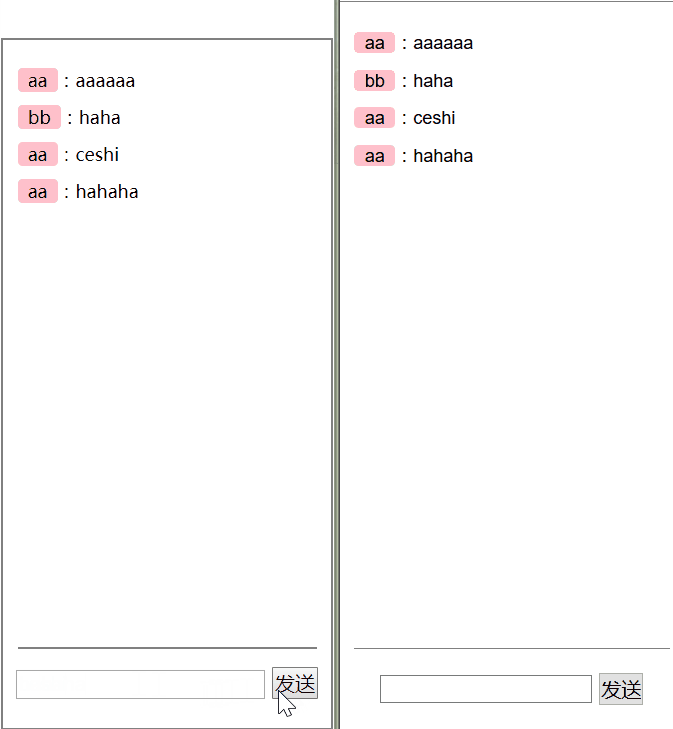
let obj = { name: '白宇', say () {} } let proxy = newProxy(obj, { get (target, key) { console.log('get ' + key) return target[key] } }) proxy.name // get name proxy.say // get say proxy.say() // get say
functioninvariant(key, action) { if (key[0] === '_') { thrownewError(`Invalid attempt to ${action} private '${key}' property`) } } let proxy = newProxy({}, { get (target, key) { invariant(key, 'get') return target[key] }, set (target, key, value) { invariant(key, 'set') if (key === 'age') { if (value > 100) { thrownewError('the age is invalid') } } target[key] = value returntrue } }) proxy.age = 120// the age is invalid proxy.age = 29 proxy._name // Invalid attempt to get private '_name' property proxy._name = 'baiyu'// Invalid attempt to set private '_name' property
set 方法不 return true,在严格模式下会报错。
has
has (target, key)
拦截 key in proxy 操作,返回一个布尔值
has 拦截对 for...in 循环不生效
1 2 3 4 5 6 7 8 9 10 11 12 13
let src = {name: '白宇'} let tar = Object.create(src) tar.age = 29 let p = newProxy(tar, { has (target, key) { console.log('in proxy') return key in target } }) console.log('name'in p) // in proxy , true for (const key in p) { console.log(p[key]) // 29, 白宇 }
deleteProperty
deleteProperty (target, key)
拦截 delete proxy[key] 操作,返回一个布尔值
如果该方法返回 false 或报错,则属性无法被删除
1 2 3 4 5 6 7 8 9 10 11 12
let obj = {_name: 'white', name: '白宇'} let p = newProxy(obj, { deleteProperty (target, key) { if (key[0] === '_') { thrownewError(`private property ${key} cannot be deleted`) } delete target[key] returntrue } }) delete p.name // 成功删除 delete p._name // 报错:private property _name cannot be deleted
当 target 为构造函数时使用,拦截 proxy 作为构造函数调用当操作。如 new proxy(...args)
1 2 3 4 5 6 7 8 9 10 11 12
functionFun(firstName, lastName) { this.fullName = lastName + firstName } let proxyFun = newProxy(Fun, { construct (target, args) { console.log(args) // ['宇', '白'] let res = new target(...args) res.age = 29 return res } }) console.log(new proxyFun('宇', '白')) // Fun {fullName: '白宇', age: 29}
Proxy.revocable()
Proxy.revocable 方法返回一个可取消的 Proxy 实例。
1 2 3 4 5
let {proxy, revoke} = Proxy.revocable({}, {}) proxy.name = '白宇' console.log(proxy.name) // 白宇 revoke() console.log(proxy.name) // 报错:Cannot perform 'get' on a proxy that has been revoked
想要在网页中使用 Service Worker,需要在我们网页的 javascript 中注册它。注册一个 Service Worker,浏览器会在后台开始一个 Service Worker 的安装步骤。
代表性的,在安装 Service Worker 期间,我们会想要缓存一些静态资源。如果所有文件全部缓存成功,Service Worker 则为 installed 状态。如果任何一个文件加载并缓存失败,则安装步骤将会失败,Service Worker 则不会被激活。不过,如果文件加载失败,也无需担心,因为 Service Worker 会重新去尝试加载。
安装步骤成功之后,接下来便是激活步骤。激活步骤可以用来处理一些旧的版本的 Service Worker 中缓存的资源。
激活成功之后,serviceWorker 就可以控制页面了,但是只针对在成功注册了 Service Worker 后打开的页面。也就是说,页面打开时有没有 Service Worker,决定了接下来页面的生命周期内受不受 Service Worker 控制。所以,只有当页面刷新后,之前不受 Service Worker 控制的页面才有可能被控制起来。
一旦 Service Worker 控制了页面,它将会有两种状态:terminated(中止状态),可以节省内存,或者在网页发起请求时,处理 fetch 和 message 事件。
下面是一个简单版本的 Service Worker 第一次安装时的生命周期图。
使用 Service Worker 的先决条件
浏览器支持
Service Worker 目前已经被 chrome、firefox、opera 支持。Edge 浏览器已经表示了支持,safari 未来也会支持 Service Worker。
需要 HTTPS
开发阶段,可以在 localhost 和 127.0.0.1 中使用 Service Worker,但是部署之后,则必需使用 HTTPS。
使用 Service Worker 我们可以劫持连接,伪造并过滤响应。这个强大的功能容易被黑客恶意使用,为了防止这种情况,我们必须使用 HTTPS 来保证连接不被干扰。
response 的 type 为 basic,说明请求的资源来自当前域名。上面的代码校验不等于 basic 直接返回,意为来自其他域名的资源不进行缓存。
Service Worker 版本更新
更新 Service Worker 需要遵从以下步骤:
更新 Service Worker javascript 文件。当用户打开我们的网站,浏览器会重新加载 Service Worker 的 js 文件,只要有改动,即会被视为新的。
开启新的 Service Worker,并触发 install 事件。
此时,旧的 Service Worker 仍然在控制当前页面,所以新的 Service Worker 将会进入 waiting 状态。
所有已打开的页面关闭之后,旧的 Service Worker 自动停止,新的 Service Worker 会在重新打开的页面生效。
一旦新的 Service Worker 生效,它的 activate 事件会被触发。
在 activate 事件回调里,一个共同的任务是 cache 管理。必须在 activate 事件清理旧版本的 Service Worker,而不是在 install 事件中清理的原因是,如果在 install 事件中清理,则包括正在控制当前页面的 Service Worker 在内的所有旧版本 Service Worker,都会被停止,使得当前页面没有可以使用的 Service Worker。
let val1: any = '卫庄' let len1: number = (<string>val1).length console.log(len1) let val2: any = true let len2: number = (val2 as string).length console.log(len2) // undefined
索引类型可以约束某一类型的属性的返回值类型。如下,因为 string 类型的属性设定了返回值类型为 string,所以属性 name 的返回值为 number 就会报错
1 2 3 4 5
interface StringArray { [index: number]: string [key: string]: string name: number // 报错:[ts] Property 'name' of type 'number' is not assignable to string index type 'string'. }
如上面定义变量 dage 的方法,dage 为 Cat 类的实例,但是类型可以是基类 Animal。
修饰符 public
public 是默认的修饰符,成员都默认为 public
1 2 3 4 5 6 7 8 9
classAnimal{ public name: string public constructor(name: string) { this.name = name } public move (discInMeters: number = 0) { console.log(`${this.name} moved ${discInMeters}m!`) } }
修饰符 private
当成员被标记成 private 时,它就不能在声明它的类的外部访问。
1 2 3 4 5 6 7 8 9
classAnimal{ private name: string public constructor(name: string) { this.name = name } }
let animal = new Animal('白凤') console.log(animal.name) // 报错:[ts] Property 'name' is private and only accessible within class 'Animal'.
classPerson{ protected name: string constructor(name: string) { this.name = name } } classEmployeeextendsPerson{ private department: string constructor(name: string, department: string) { super(name) this.department = department } introduce (): void { console.log(`Hi, I'm ${this.name} and I work in ${this.department}!`) } } let weizhuang = new Person('卫庄') // weizhuang.name // 报错:[ts] Property 'name' is protected and only accessible within class 'Person' and its subclasses. let genie = new Employee('盖聂', '秦国') genie.introduce()
classPerson{ protected name: string protected constructor(name: string) { this.name = name } } // let weizhuang = new Person('卫庄') // 报错:[ts] Constructor of class 'Person' is protected and only accessible within the class declaration.
修饰符 readonly
readonly 将属性设置为只读,初始化后不可修改。
初始化方式:
声明时
构造函数里
1 2 3 4 5 6 7 8 9
classDog{ readonly name: string readonly numOfLegs: number = 4 constructor(name: string) { this.name = name } } let diandian = new Dog('点点') diandian.name = '贝贝'// 报错:[ts] Cannot assign to 'name' because it is a constant or a read-only property.
当在 tsconfig.json 中配置 noImplicitThis 为 true 时,this 表达式的值为 any 类型时,会生成一个错误。提供一个具有类型的 this 参数,告诉 typescript 函数期待在那个对象上调用,就不会报错了。
1 2 3 4 5 6 7 8 9 10 11
interface Card { suit: string card: number } functiontestThis() { console.log(this.card) // 报错:'this' implicitly has type 'any' because it does not have a type annotation. } functiontestThis(this: Card) { // 提供 this 参数,就不报错了 console.log(this.card) }
functionidentify<T>(x: T): T{ console.log(x.length) // 报错:Property 'length' does not exist on type 'T'. return x }
因为 x 可能是不包含 length 属性的类型,如 number 类型。
我们可以把泛型变量 T 当做类型的一部分使用,而不是整个类型,增加了灵活性。
1 2 3
functionidentify2<T>(x: T[]): T[] { return x }
如上,泛型变量 T 代表的是数组类型的参数 x 中的元素的类型,而不是参数整体的类型。
泛型接口
为泛型函数 identify 定义泛型类型的接口
1 2 3 4
interface indentifyFn { <T>(x: T): T } let myIdentify: indentifyFn = identify
可以把泛型参数当作整个接口的一个参数
1 2 3 4
interface indentifyFn2<T> { (x: T): T } let myIdentify2: indentifyFn2<string> = identify
泛型类
1 2 3 4 5 6 7 8 9 10
class genericClass<T> { a: T static b: T // 报错:Static members cannot reference class type parameters. add: (x: T, y: T) => T } let myGenericClass = new genericClass<number>() myGenericClass.a = 12 myGenericClass.add = function(x, y) { return x + y }
functionextend<T, U>(first: T, second: U): T & U{ let result = <T & U>{} for (let key in first) { ;(<any>result)[key] = first[key] } for (const key in second) { if (second.hasOwnProperty(key)) { ;(<any>result)[key] = second[key] } } return result }
functionpadLeft(value: string, padding: string | number) { if (typeof padding === 'number') { returnArray(padding + 1).join(' ') + value } else { return padding + value } }
如果一个值是联合类型,我们只能访问此联合类型的所有类型里共有的成员。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
interface Bird { fly() layEggs() } interface Fish { swim() layEggs() } functiongetPet(): Bird | Fish{ return <Bird | Fish>{} } let pet = getPet() pet.layEggs() // pet.fly() // 报错:Property 'fly' does not exist on type 'Bird | Fish'. Property 'fly' does not exist on type 'Fish'.
let s = 'abc' // s = undefined // 报错:Type 'undefined' is not assignable to type 'string' // s = null // 报错:Type 'null' is not assignable to type 'string'
可选参数和可选属性
使用了 --strictNullChecks,可选参数会被自动地加上 | undefined:
1 2 3 4 5 6
functionf(a: number, b?: number): number{ return a + (b || 0) } f(1, 3) f(1, undefined) // f(1, null) // 报错:Argument of type 'null' is not assignable to parameter of type 'number | undefined'.
可选属性也会有同样的处理:
1 2 3 4 5 6
class C { constructor(public a: number, public b?: number) {} } let cc = new C(1, undefined) let cc2 = new C(1, 4) // let cc3 = new C(1, null) // 报错:Argument of type 'null' is not assignable to parameter of type 'number | undefined'.
type Easing = 'ease-in' | 'ease-out' | 'ease-in-out' functiontranslate(easing: Easing) { if (easing === 'ease-in') { } elseif (easing === 'ease-out') { } else { } } translate('ease-in-out') // translate('linear') // 报错:[ts] Argument of type '"linear"' is not assignable to parameter of type 'Easing'.
declaremodule '*!text' { const content: string exportdefault content } // Some do it the other way around. declaremodule 'json!*' { const value: any exportdefault value }
现在你可以就导入匹配”!text”或”json!“的内容了。
1 2
import fileContent from'./xyz.txt!text' import data from'json!http://example.com/data.json'
let validators: {[s: string]: Validation.StringValidator;} = {} validators['Letters Only'] = new Validation.LettersOnlyValidator() validators['Zip Code'] = new Validation.ZipCodeValidator()
for (const s of strings) { for (const name in validators) { const isMatch = validators[name].isAcceptable(s) console.log(`${s}${isMatch ? 'matches' : 'does not match'}${name}`) } }
下一步,必须调用遍历器对象的 next 方法,使得指针移向下一个状态。也就是说,每次调用 next 方法,内部指针就从函数头部或上一次停下来的地方开始执行,直到遇到下一个 yield 表达式(或 return 语句)为止。换言之,Generator 函数是分段执行的,yield 表达式是暂停执行的标记,而 next 方法可以恢复执行。
1 2 3 4 5 6 7 8 9 10 11
hw.next() // { value: 'hello', done: false }
hw.next() // { value: 'world', done: false }
hw.next() // { value: 'ending', done: true }
hw.next() // { value: undefined, done: true }
总结一下,调用 Generator 函数,返回一个遍历器对象,代表 Generator 函数的内部指针。以后,每次调用遍历器对象的 next 方法,就会返回一个有着 value 和 done 两个属性的对象。value 属性表示当前的内部状态的值,是 yield 表达式后面那个表达式的值;done 属性是一个布尔值,表示是否遍历结束。
function* iterTree(tree) { if (Array.isArray(tree)) { for (let i = 0; i < tree.length; i++) { const element = tree[i] yield* iterTree(element) } } else { yield tree } }
Symbol 是ES6引入的一种新的原始数据类型,表示独一无二的值。 Symbol 值通过 Symbol 函数生成。Symbol 函数前不能使用 new 命令,否则会报错。这是因为生成的 Symbol 是一个原始类型的值,不是对象。也就是说,由于 Symbol 值不是对象,所以不能添加属性。基本上,它是一种类似于字符串的数据类型。
1 2 3 4
let a = Symbol() console.log(typeof a) // symbol
let c = newSymbol() // TypeError: Symbol is not a constructor
Symbol 函数可以接受一个字符串作为参数,表示对 Symbol 实例的描述,主要是为了在控制台显示,或者转为字符串时,比较容易区分。
如果 Symbol 的参数是一个对象,就会调用该对象的 toString 方法,将其转为字符串,然后才生成一个 Symbol 值。
1 2 3 4 5
let a = Symbol('haha') console.log(a) // Symbol(haha)
let b = Symbol({name: 'weizhuang'}) console.log(b); // Symbol([object Object])
注意,Symbol 函数的参数只是表示对当前 Symbol 值的描述,因此相同参数的 Symbol 函数的返回值是不相等的。
1 2 3 4 5 6 7
let a = Symbol('zhuang') let d = Symbol('zhuang') console.log(a === d); // false
let e = Symbol() let f = Symbol() console.log(e === f); // false
Symbol 与其他数据类型
Symbol 值不能与其他类型的值进行运算,会报错。
1 2 3 4
let a = Symbol('zhuang') a + 'lian'// TypeError: Cannot convert a Symbol value to a string a + 10// TypeError: Cannot convert a Symbol value to a number a + true// TypeError: Cannot convert a Symbol value to a number
console.log(Boolean(a)); // true console.log(Number(a)); // TypeError: Cannot convert a Symbol value to a number
作为属性名的 Symbol
Symbol 值可以作为对象的属性名。由于每一个 Symbol 值都是不相等的,这样就可以保证不会出现同名的属性名。
1 2 3 4 5
let a = Symbol('a') let obj = { [a]: 'weizhuang' } console.log(obj[a]); // weizhuang
注意,Symbol 值作为对象属性名时,不能用点运算符。
属性名的遍历
Symbol 作为属性名,该属性不会出现在 for…in、for…of 循环中,也不会被 Object.keys()、Object.getOwnPropertyNames()、JSON.stringify() 返回。但是,它也不是私有属性,有一个 Object.getOwnPropertySymbols 方法,可以获取指定对象的所有 Symbol 属性名。
Object.getOwnPropertySymbols 方法返回一个数组,成员是当前对象的所有用作属性名的 Symbol 值。
1 2 3 4 5 6 7 8 9 10 11 12
let a = Symbol('a') let obj = { [a]: 'weizhuang', b: 'honglian' } for (let key in obj) { console.log(key + ': ' + obj[key]); // b: honglian } console.log(Object.getOwnPropertyNames(obj)); // ["b"] console.log(Object.keys(obj)); // ["b"] console.log(JSON.stringify(obj)); // {"b":"honglian"} console.log(Object.getOwnPropertySymbols(obj)); // [Symbol(a)]
另一个新的 API,Reflect.ownKeys 方法可以返回所有类型的键名,包括常规键名和 Symbol 键名。
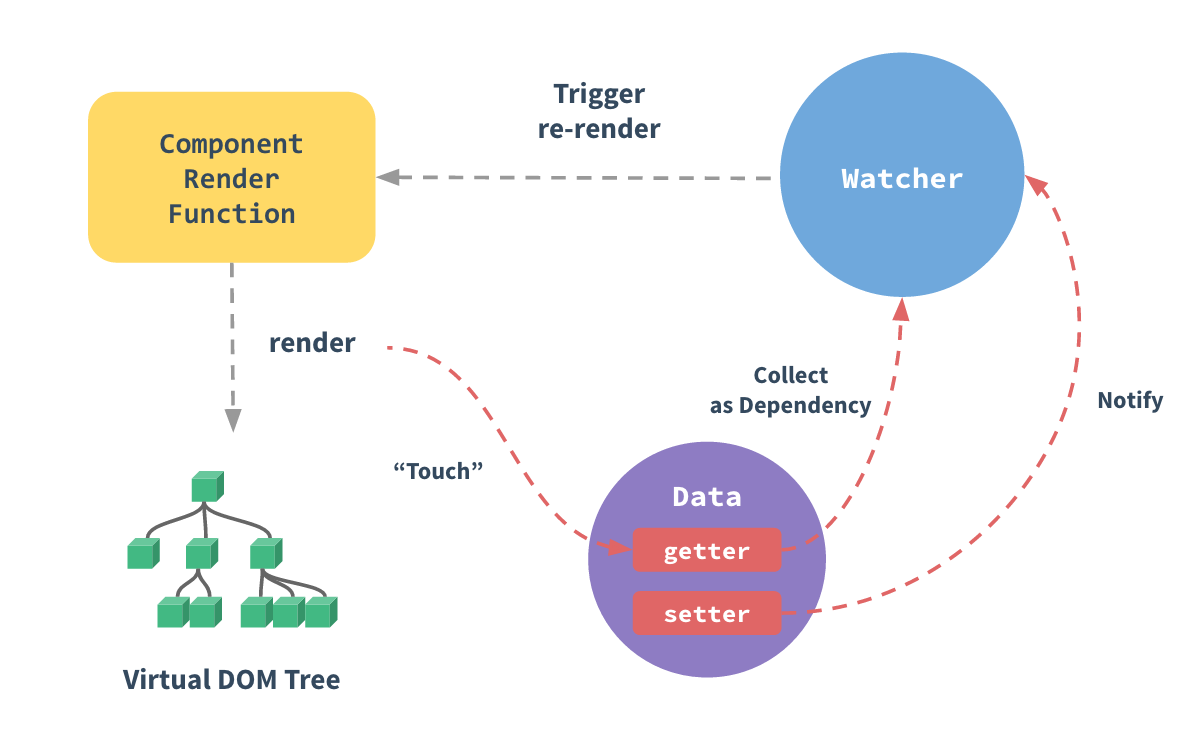
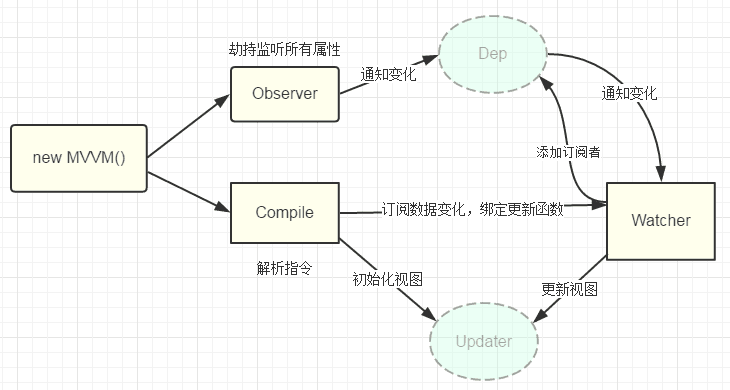
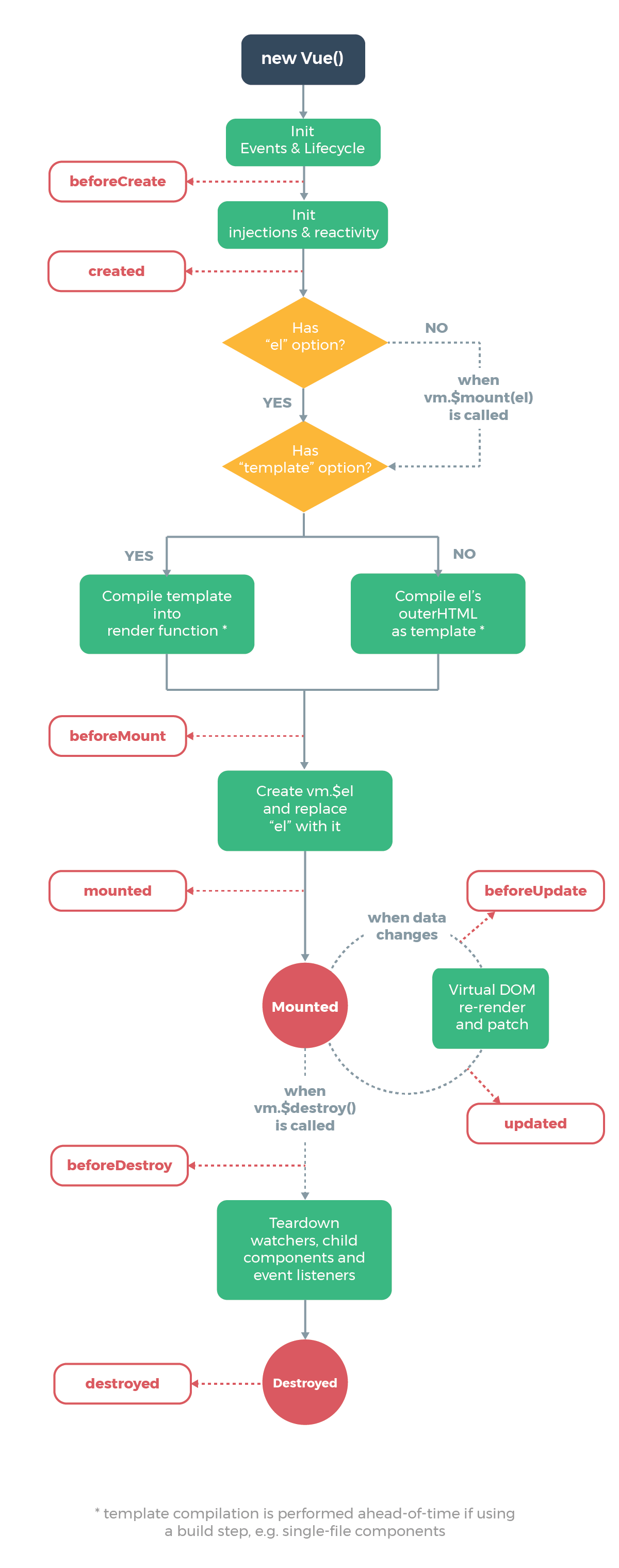
functionVue(option){ this.$option = option; // 将 option 选项对象的 data 属性,保存到变量 data和 vm 的 $data 属性 let data = this.$data = this.$option.data; let vm = this; // 遍历 data 对象的所有属性,添加 vm 代理 Object.keys(data).forEach(function(key){ vm._proxy(key); }) }
Vue.prototype = { // 代理方法 _proxy (key){ let vm = this; // 在 vm 实例上添加对应的属性,实现对 $data 对象上的属性的代理 Object.defineProperty(vm, key, { configurable: false, // 不可重新定义 enumerable: true, // 可枚举 // 代理读 get: function proxyGetter(){ return vm.$data[key]; }, // 代理写 set: function proxySetter(newVal){ vm.$data[key] = newVal; } }) } }
compileElement: function(el) { var childNodes = el.childNodes, // 获取所有子节点 me = this; // 遍历子节点 [].slice.call(childNodes).forEach(function(node) { var text = node.textContent; var reg = /\{\{(.*)\}\}/;
if (me.isElementNode(node)) { // 元素节点,解析指令 me.compile(node);
var me = this, val = this._getVMVal(vm, exp); node.addEventListener('input', function(e) { var newValue = e.target.value; if (val === newValue) { return; }
me._setVMVal(vm, exp, newValue); val = newValue; }); },
_getVMVal: function(vm, exp) { var val = vm._data; exp = exp.split('.'); exp.forEach(function(k) { val = val[k]; }); return val; },
_setVMVal: function(vm, exp, value) { var val = vm._data; exp = exp.split('.'); exp.forEach(function(k, i) { // 非最后一个key,更新val的值 if (i < exp.length - 1) { val = val[k]; } else { val[k] = value; } }); }
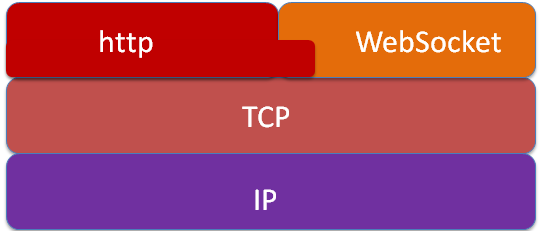
Long Polling Long Polling 的原理与 ajax 轮询的原理差不多,都是采用轮询的方式,它是 Polling 的一种改进。客户端发送请求到服务器后,服务器并不立即响应客户端,而是保持住这次连接,当有新的数据时,才返回给客户端,客户端接收到数据,进行展示,再立即发送一个新的请求给服务器,并重复这个过程。如果服务器的数据长期没有更新,一段时间后,这个请求就会超时,客户端收到超时消息后,再立即发送一个新的请求给服务器。
从上面可以看出,这两种方式都需要不断的建立 HTTP 连接,然后等待服务器处理。
ajax 轮询假如某段时间内服务器没有更新的数据,但是客户端仍然需要定时发送请求,服务器再把以前的老数据返回过来,客户端拿到老数据,再把没有变化的数据再显示出来,即这段时间内,客户端和服务器会定时交换不变的数据信息,这样既浪费了带宽,又浪费了 CPU 的利用率。
Long Polling 虽然解决了带宽和 CPU 利用率的问题,但是如果服务器的数据更新的过快,服务器在返回给客户端一次数据包之后,只能等待客户端再次发送一次请求来之后,才能发送下一个数据包给客户端。在服务器两次返回数据之间,需要等待客户端接收到数据之后处理数据的时间,以及客户端再次发送连接请求后,服务器验证客户端的鉴别信息,并成功建立连接的时间,在网络拥塞的情况下,这个应该是用户不能接受的。
在 worker 线程中可以运行任意的代码,以下情况除外:不能直接在 worker 线程中操纵 DOM 元素, 或者使用某些 window 对象中默认的方法和属性。 但是 window 对象中很多的方法和属性是可以使用的,包括 WebSockets,以及诸如 IndexedDB 和 FireFox OS 中独有的 Data Store API 这一类数据存储机制。
var onmessage = event => { let n = event.data; console.log('子线程接收到主线程发送的消息'); let result = fibonacci(n); postMessage(result); console.log('子线程向主线程发送消息'); }